AMT Standards and Guidelines
Design Principles
- Core or Use Case-Specific. Each view needs to be defined as "core" (general purpose) or part of a well-defined and named use case (e.g. "early warning system"). The deployment mechanism thus would always deploy core views, while providing an optional mechanism for deploying one-or-more use-case specific views.
- Granular Data. Data should not be "rolled up" or aggregated. As views, calculations will be expensive. Furthermore any algorithms placed here would restrict the usefulness of the view - as the algorithm would only be useful in a small set of circumstances.
- DevOps Friendly Deploy. Views should be deployable using a tool that provides logging, idempotency, and can perform remote deployments (given valid database credentials).
- SQL Server and PostgreSQL Parity. The core views should be maintained in parallel for both database providers. It will not always (often?) be feasible to maintain parallel versions of the use-case specific views.
- Dimensional Modeling. Views should be created as either Dimensions or Facts (although there may be some trivial exceptions), ideally adhering more to Star Schema design than a Snowflake Schema. Roughly speaking:
- Facts contain measure values that can be used in calculations (count, sum, multiply, etc) - thus numeric or Boolean (as 0/1). Facts link to Dimensions for attribute data. Each Fact would be unique in some way, for example as occurring on a particular date.
- Dimensions contain attributes or labels for the data - thus could be strings, Dates, etc. Each Dimension row should be unique.
- Support Multiple Data Standards. Views should support data standards 2.2, 3.1, and 3.2 when feasible.
- Natural Key Usage. When the source table's natural key is a composite key, concatenate the values together to form a string surrogate key.
- LastModifiedDate. Each dimension view should have a
LastModifiedDatecolumn that selects the most recentLastModifiedDatevalue from all of the source tables used by the view. - Avoid Null. Cast
nullvalues to empty strings, false, or 0 as appropriate. If a nullable field is a string, consider casting to something meaningful to an end-user, for example, "Unknown". - Cast Numbers as Strings. If a value is a number in the ODS database, cast it to a string value (
varchar) unless it makes sense to use the value in a calculation. For example, a Data Analyst is unlikely to be running a sum overSchoolYear, so cast it to a string instead of leaving it as an integer. This improves the conceptual model provided to downstream users. Another example is a numeric identifier, such asEducationOrganizationId. As there are no cases where one will perform arithmetic onEducationOrganizationId, it should always be treated as a string in aSELECTstatement.
Naming
Schemas
All views for this component, whether Dimension, Fact, or other, will be in the analytics schema.
All configuration tables, functions, or stored procedures will be in the analytics_config schema.
View Names
- View names will be descriptive of their purpose.
- Views that belong to a use case collection should have the code name of that collection as a prefix.
- Fact-style views must have the word "Fact" as a suffix.
- Dimension-style views must have the word "Dim" as a suffix.
- View names must be restricted to 63 characters or fewer, due to the name length restriction in PostgreSQL.
- Names should be singular unless one row contains multiple of something.
- View names should use CamelCase.
Examples:
| Purpose | Name |
|---|---|
| Dimension view for students | analytics.StudentSchoolDim |
| Dimension view for schools | analytics.SchoolDim |
| Fact a student's grades in a section, which belongs to the Early Warning System Collection | analytics.ews_StudentSectionGradeFact |
| Mapping configuration table | analytics_config.DescriptorConstant |
Coding Standards
Language
- Where possible, utilize ANSI-SQL for maximum portability between SQL Server and PostgreSQL:
- Do not use identifier quoting — either
[...]or"...". - Prefer the
COALESCEfunction overISNULLwhen replacing a null value with a concrete value.
- Do not use identifier quoting — either
- Joins should include the word "INNER" or "OUTER" for maximum clarity.
- Use comments to explain anything that might be nonintuitive.
- Avoid aliasing, where possible. Aliases make the reader work harder to understand the query. However, there will be times when aliases are required, for example when needing to join twice to the same table. Very long table names can sometimes benefit from a reasonable alias as well, to keep line lengths from becoming excessive.
Formatting
Formatting need not be a strict exercise — adherence to absolute precision in SQL scripts, where various tools have differing (or no) ability to help format a file, is difficult to achieve. The code reviewer should ensure that the file is readable and meets at least the spirit of the following preferences.
- Place the
CREATEstatement on a line by itself. - For the keywords
WITH,SELECT,FROM,WHERE,GROUP BY,HAVING.- Each should be on a line by itself.
- Indent once except when part of a CTE or sub-query.
- Within each clause:
- Each column or condition should be on a line by itself.
- Indent twice (preferably 4 spaces rather than tab character).
- This includes joins.
- In the
ONclause for joins:- Each criteria should be on a line by itself.
- Each criteria should have an additional indentation.
- Case does not matter — but should be consistent within a query.
Formatting Examples
Let's look at a poor example of query formatting:
CREATE VIEW [analytics].[UserDimension] AS SELECT [Staff].[StaffUSI] as [UserKey], [StaffElectronicMail].ElectronicMailAddress as [UserEmail], ( SELECT MAX([LastModifiedDate]) from (VALUES ([Staff].[LastModifiedDate]) -- [StaffElectronicMail] does not have a [LastModifiedDate] ,([StaffElectronicMail].[CreateDate]) ,([ElectronicMailType].[LastModifiedDate]) ) as value([LastModifiedDate]) ) as [LastModifiedDate] FROM [edfi].[Staff] join [edfi].[StaffElectronicMail] ON [Staff].[StaffUSI] = [StaffElectronicMail].StaffUSI JOIN [edfi].[ElectronicMailType] ON [StaffElectronicMail].[ElectronicMailTypeId] = [ElectronicMailType].[ElectronicMailTypeId] WHERE [ElectronicMailType].[CodeValue] = 'Work'
Problems with this example:
- Need to bring the create statement onto one line.
- The
SELECTkeyword should be indented. - First column in select statement is on the same line as
SELECT. - Mix of case in the SQL keywords (e.g.,
SELECTandfromare inconsistent). - Preference to include keyword
INNERon the joins. - Join conditions must be separated.
- The
WHEREcondition should be on a line by itself.
The following shows a more readable example:
CREATE VIEW analytics.UserDimension AS
SELECT
Staff.StaffUSI as UserKey,
StaffElectronicMail.ElectronicMailAddress as UserEmail,
( SELECT
MAX(LastModifiedDate)
FROM (VALUES (Staff.LastModifiedDate)
-- StaffElectronicMail does not have a LastModifiedDate
,(StaffElectronicMail.CreateDate)
,(ElectronicMailType.LastModifiedDate)
) as value(LastModifiedDate)
) as LastModifiedDate
FROM
edfi.Staff
INNER JOIN
edfi.StaffElectronicMail
ON
Staff.StaffUSI = StaffElectronicMail.StaffUSI
INNER JOIN
edfi.ElectronicMailType
ON
StaffElectronicMail.ElectronicMailTypeId = ElectronicMailType.ElectronicMailTypeId
WHERE
ElectronicMailType.CodeValue = 'Work'
Adding Files to the Project
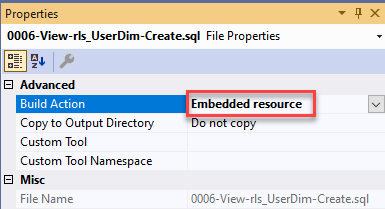
All SQL files added to the project must bed Embedded Resources instead of "regular files". In Visual Studio, many developers just copy and paste an existing file to create a new one; this will keep the necessary property value.
To see this in Visual Studio, right-click a file in the Solution Explorer and choose Properties. Desired setting:
Testing
The Analytics Middle Tier unit test project includes tests both for the C# code and, more importantly, for the views themselves. These tests serve as full regression tests and should be modified any time a view is changed. All views should be "unit tested" with full coverage. For example, if someone comments out a left outer join condition, then a test should fail.
For more information on the test framework, see Unit Test Framework.
Contents