The Ed-Fi “Classic Dashboards” are no longer supported through the Ed-Fi Alliance. You can still receive support and maintenance through the Ed-Fi vendor community. Please look at any of the vendors’ dashboard solutions on the Registry of Ed-Fi Badges or the Ed-Fi Starter Kits if you are looking for a visualization solution to use with the Ed-Fi ODS. This documentation will remain available to assist existing Classic Dashboard implementers.
ETL Developers' Guide - Running the ETL Application
This page covers how the ETL is executed and maintained in production environments.
Execution
Assuming you've configured the application, the simplest way to run the ETL is by double-clicking on the executable. The processing steps are covered in detain in the technical article Overview of the ETL Application Runtime Process.
Scheduling ETL Execution
Most production implementations rely on a scheduler to run the metric calculations. Depending on the amount of time it takes to execute the ETL, you may want to schedule the ETL application to run overnight or multiple times a day. The simplest way is to use Windows Task Scheduler to schedule runs.
Monitoring Health via Logging
The ETL application has varying levels of logging that can be output to the Console screen or written to a database. See the Logging section below for details. The default log database is name EtlLogDb.
Continuous Integration and Deployment
If you plan to extend or customize the Ed-Fi Dashboards now or in the future, it is recommended you set up a continuous integration environment to build the packages for the Database, ETL, and UI components.
As an example, we'll look at the environment used by the Ed-Fi Dashboard developers. The Ed-Fi Dashboards development team used TeamCity for their continuous integrations build solution and Octopus Deploy for their deployment solution. The integration setup shown is an example, not a requirement.
Ed-Fi Dashboard 3.0 Integration and Deployment Ecosystem
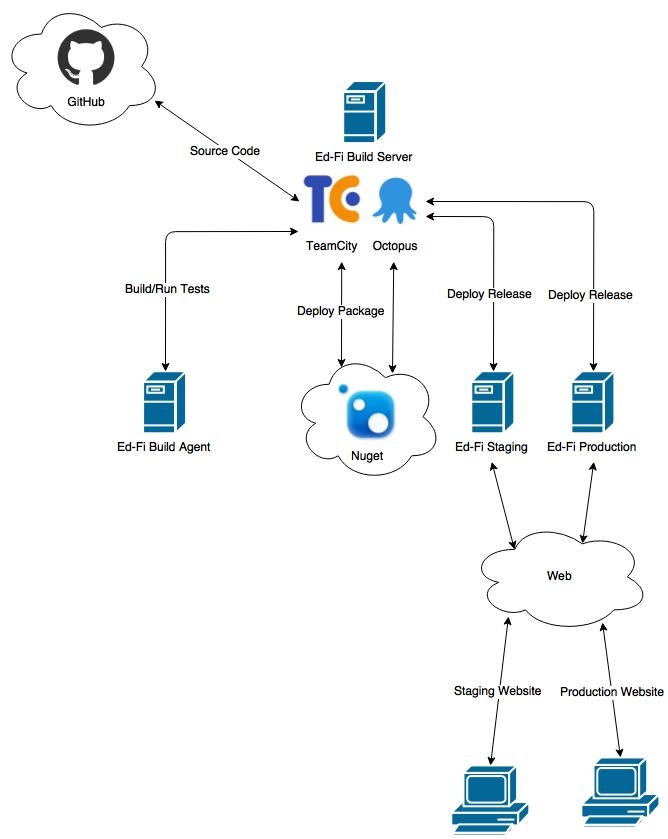
Continuous Integration Build Process
When new code is submitted to the development repository in GitHub, the TeamCity instance will start a new build on the agent machine. The new code is pushed to the build agent and executes the following steps:
- Create/update any require databases for unit and integration tests.
- Compile the source code.
- Execute unit and integration tests.
The build agent will report any failing steps for investigation. After the development branch has been verified, the code is merged into the master repository in GitHub. TeamCity will compile the source code, create a NuGet package, and upload the package to the NuGet feed.
Our TeamCity instance has a configuration for each of the dashboard components:
- Dashboard UI - Web Application
- Databases- Database Packaging
- ETL - ETL Application

Deployment Process
When Octopus detects the new NuGet package, it downloads the package and starts the deployment process to the staging server. Octopus will deploy the package to the staging server, update any app or Web.config settings, create/update any databases, and execute the ETL. The Dashboard website deployment follows a similar pattern. Once the staging dashboard website and ETL are verified, the code can be promoted to production which follows a similar deployment process.
Special Considerations
This section has guidance for special situations.
Large Datasets
The ETL application was written to handle very large datasets, and was tested on datasets containing 1,000,000+ students. In the Ed-Fi context, a dataset is considered "large" when it contains data related to 250,000+ students.
For large datasets, it is recommended that File Buffer Bulk Writing functionality be enabled. This is because most of the execution time is in the writing of data to the target databases. Directions for setting the File Buffer Bulk Writing option can be found in the Application Configuration section.
Troubleshooting
This section provides troubleshooting hints.
Logging
The ETL Log database holds any exceptions that occur during the ETL runtime process. The ETL uses Serilog to log the events. The dbo.Logs table contains specific information about Errors, Warnings, and other ETL information. The Properties column contains dynamic properties such as StudentUSI, SchoolId, and so forth. The ETL Log database also provides two views: dbo.LogEntries for reading the main log messages and dbo.LogProperties for reading the dynamic properties.
The Level column describes the log event level. Serilog documentation describes the levels as:
| Level | Usage |
|---|---|
Verbose | Verbose is the noisiest level, rarely (if ever) enabled for a production app. |
Debug | Debug is used for internal system events that are not necessarily observable from the outside, but useful when determining how something happened. |
Information | Information events describe things happening in the system that correspond to its responsibilities and functions. Generally these are the observable actions the system can perform. |
Warning | When service is degraded, endangered, or may be behaving outside of its expected parameters, Warning level events are used. |
Error | When functionality is unavailable or expectations broken, an Error event is used. |
Fatal | The most critical level, Fatal events demand immediate attention. |
The log level is configured in the runtime app.config file. The default log level is set to Information which includes Warnings, Errors, and Fatal exceptions in the log.
If there are a large number of exceptions during an ETL run, logging may degrade performance. If performance is a concern, the logging level can be changed to a lower log level (e.g., Error) to log fewer issues.
Out of Memory Exceptions
For large datasets, the ETL will need sufficient memory to perform the metric calculations. We recommend double the RAM in relation to the database size. For example, a 16 GB ODS will perform best with 32 GB of RAM.
If there is sufficient memory, check that the CacheAllQueries configuration option is set to false.
SQL Query Timeouts
If the ETL experiences SQL timeouts, the timeout can be increased through the configuration parameter SqlQueryTimeout.
If timeouts still occur the CacheAllQueries option can be enabled. It will store query data in memory and SQL will not hold an open connection. When setting this option, ensure there is enough RAM to support the ETL operation.
Primary Key Violations
There may be data or configuration that results in duplicate metrics being calculated. These errors will not cause the ETL to fail, but they will hinder performance. The EtlLog database will contain records that caused the primary key violations for investigation into either incorrect data in the ODS or an incorrect configuration.